
Wprowadzenie do Grep i regex
Grep i wyrażenia regularne są narzędziami, które służą do wyszukiwania i manipulowania tekstem w plikach. Grep to polecenie używane w systemach operacyjnych Unix i Unix-like, które służy do wyszukiwania wzorców tekstowych w plikach lub strumieniach danych.
Nazwa „grep” pochodzi od słów „global regular expression print”, co odzwierciedla pierwotne zastosowanie narzędzia – globalne wyszukiwanie i drukowywanie linii pasujących do wzorca. Grep umożliwia elastyczne wyszukiwanie i analizę tekstu na podstawie określonego wzorca.

Sprawdź, czego nauczysz się dzięki kursowi Grafany!
Udostępniamy darmowo ponad godzinny materiał z kursu. Przekonaj się, że jest idealny dla Ciebie!
Chcesz wziąć udział w kursie? Kliknij w link i obejrzyj co Cię czeka: https://asdevops.pl/demo-grafana/
Wyrażenia regularne (regex)
Wyrażenia regularne, znane również jako regex (od angielskiego „regular expressions”), to sekwencje znaków, które definiują wzorce tekstowe. Pozwalają na bardziej zaawansowane i precyzyjne wyszukiwanie wzorców w tekście niż zwykłe dopasowywanie literałów. Wyrażenia regularne składają się z różnych elementów, takich jak litery, cyfry, znaki specjalne i metaznaki, które tworzą reguły dopasowywania. Są one wszechstronnym narzędziem do manipulacji i przetwarzania tekstowych danych, umożliwiając wyszukiwanie, zastępowanie, sprawdzanie poprawności formatu, ekstrakcję informacji i wiele innych operacji.
Grep i wyrażenia regularne są szeroko stosowane w różnych dziedzinach, takich jak programowanie, analiza logów, przetwarzanie tekstu, administracja systemami i wiele innych. Ich siła tkwi w możliwości precyzyjnego określania i znajdowania wzorców tekstowych, co przyczynia się do efektywnego przetwarzania i manipulowania danymi tekstowymi.
Przykłady zastosowań Grep i wyrażeń regularnych
Wyszukiwanie linii zawierających określone słowo
Można użyć Grep do znalezienia wszystkich linii w pliku zawierającym konkretne słowo lub frazę. Na przykład:
grep "visitors" Tekst.txtwyszuka wszystkie linie zawierające słowo „visitors” w pliku „Tekst.txt”.

Filtrowanie wyników
Można użyć Grep do filtrowania wyników na podstawie określonego wzorca. Na przykład:
ls -l | grep ".txt"wyświetli tylko pliki z rozszerzeniem „.txt” w bieżącym katalogu.

Wyszukiwanie z wykorzystaniem wyrażeń regularnych
Wyrażenia regularne umożliwiają bardziej zaawansowane wyszukiwanie. Na przykład:
grep "^[A-Z]" Tekst.txtwyszuka wszystkie linie w pliku, które zaczynają się od dużej litery.
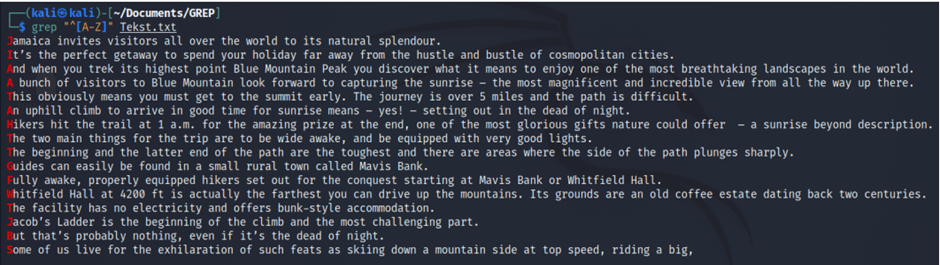
Sprawdzanie poprawności formatu
Wyrażenia regularne można użyć do sprawdzania poprawności formatu danych. Na przykład, można sprawdzić, czy podany ciąg znaków jest poprawnym adresem e-mail lub numerem telefonu.
Sprawdzanie adresu e-mail:
grep -P "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$" adresy_email.txt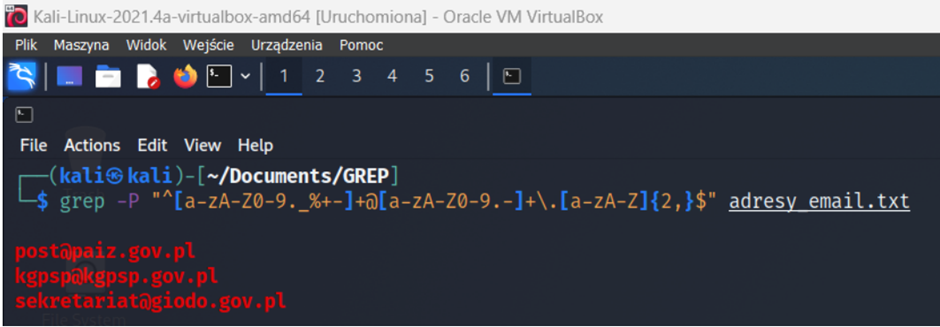
Sprawdzanie numeru telefonu:
grep -P "^\+?\d{1,3}[-.\s]?\(?\d{1,3}\)?[-.\s]?\d{1,4}[-.\s]?\d{1,4}[-.\s]?\d{1,9}$" numery_telefonow.txt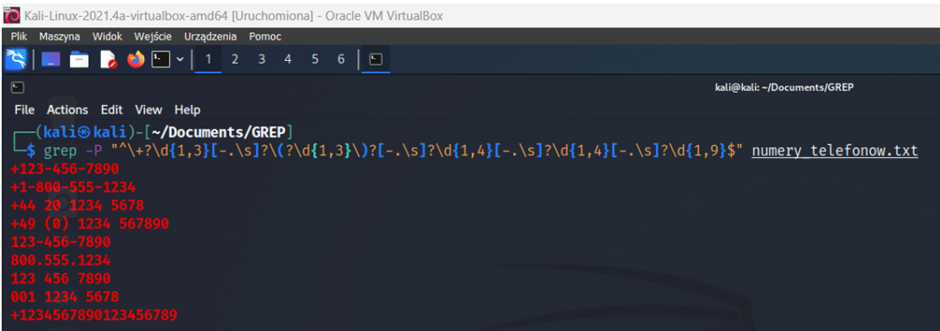
W powyższych przykładach użyto wyrażeń regularnych, które sprawdzają, czy dany ciąg znaków pasuje do określonego wzorca adresu e-mail lub numeru telefonu. Jeśli wyrażenie regularne dopasuje się do ciągu znaków, to oznacza, że format jest poprawny.
W przeciwnym razie, jeśli brak dopasowania, to format jest nieprawidłowy. Oczywiście, wyrażenia regularne mogą być dostosowane do konkretnych wymagań dotyczących formatu adresu e-mail lub numeru telefonu.
Analiza logów
Grep jest często używany do analizy plików dziennika (logów). Można go użyć do wyszukiwania określonych zdarzeń, filtrowania błędów lub monitorowania działania systemu. Powyższe przykłady pokazują tylko niewielką część możliwości Grep i wyrażeń regularnych. Są one bardzo wszechstronnymi narzędziami do manipulowania i przetwarzania tekstu, które znajdują zastosowanie w wielu dziedzinach.
Składnia Grep
Polecenie Grep (Global Regular Expression Print) służy do wyszukiwania wzorców tekstowych w plikach lub strumieniach danych. Składnia ogólna polecenia Grep wygląda następująco:
grep [opcje] wzorzec [pliki]Poszczególne elementy składni:
– `grep`: Jest to samo polecenie Grep.
– `[opcje]`: Opcje są dodatkowymi flagami, które można użyć w celu dostosowania działania polecenia Grep.
Przykłady opcji to:
`-i` (ignorowanie wielkości liter),
`-r` (rekurencyjne przeszukiwanie podkatalogów),
`-n` (wyświetlanie numerów linii) i wiele innych.
Opcje są opcjonalne i można ich używać w zależności od potrzeb.
– `wzorzec`: Jest to wzorzec tekstowy, który chcemy wyszukać w plikach. Może to być pojedyncze słowo, fraza lub wyrażenie regularne.
– `[pliki]`: To opcjonalny argument, który wskazuje na konkretne pliki w których chcemy wyszukiwać wzorzec. Można podać jeden lub więcej plików, oddzielając je spacją. Jeśli `[pliki]` nie jest podane, Grep oczekuje danych wejściowych ze strumienia danych.
Przykłady użycia polecenia Grep do wyszukiwania wzorców w plikach tekstowych
Wyszukiwanie wzorca w pojedynczym pliku:
Ten przykład wyszukuje w pliku „plik.txt” linie zawierające słowo „przykład”.
grep "przykład" plik.txtWyszukiwanie wzorca w wielu plikach:
Ten przykład wyszukuje w plikach „plik1.txt” i „plik2.txt” linie zawierające słowo „przykład”.
grep "przykład" plik1.txt plik2.txtIgnorowanie wielkości liter:
Ten przykład wyszukuje w pliku „plik.txt” linie zawierające słowo „przykład”, niezależnie od tego, czy jest zapisane małymi czy dużymi literami.
grep -i "przykład" plik.txtRekurencyjne przeszukiwanie podkatalogów:
Ten przykład rekurencyjnie przeszukuje wszystkie pliki tekstowe wewnątrz katalogu „katalog” i jego podkatalogów w poszukiwaniu linii zawierających słowo „przykład”.
grep -r "przykład" katalogWyświetlanie numerów linii:
Ten przykład wyszukuje w pliku „plik.txt” linie zawierające słowo „przykład” i wyświetla również numer każdej znalezionej linii.
grep -n "przykład" plik.txtWyświetlanie tylko liczby pasujących linii, ale nie samych linii:
Ten przykład wyszukuje liczbę linii zawierających słowo „przykład”:
grep -c "przykład" plik.txtWyświetlanie linii, które nie pasują do wzorca:
Ten przykład wyszukuje wszystkie linie w pliku „plik.txt”, które nie zawierają słowa „przykład”.
grep -v "przykład" plik.txtWyświetlanie tylko nazw plików zawierających pasujące wyniki:
Ten przykład wyszukuje nazwy plików, w których występuje słowo „przykład”.
grep -l "przykład" plik1.txt plik2.txtWyświetlanie n linii kontekstu po każdym dopasowaniu:
Ten przykład wyszukuje linie zawierające słowo „przykład” oraz dwie linie kontekstu po każdym dopasowaniu.
grep -A 2 "przykład" plik.txtWyświetla n linii kontekstu przed każdym dopasowaniem:
Ten przykład wyszukuje linie zawierające słowo „przykład” oraz dwie linie kontekstu przed każdym dopasowaniem.
grep -B 2 "przykład" plik.txtWyszukiwanie wzorców na początku lub końcu linii:
Można użyć znaków specjalnych `^` i `$` w wyrażeniach regularnych, aby wyszukiwać wzorce na początku lub końcu linii. Na przykład:
grep "^Początek" plik.txt
grep "Koniec$" plik.txtPierwsze polecenie wyświetli linie rozpoczynające się od słowa „Początek”, a drugie polecenie wyświetli linie kończące się słowem „Koniec” w pliku „plik.txt”.
Użycie wyrażeń regularnych rozszerzonych:
Ten przykład wyszuka linie zawierające numery telefonów w formacie XXX-XXX-XXXX.
grep -E "[0-9]{3}-[0-9]{3}-[0-9]{4}" plik.txtPowyższe przykłady ilustrują podstawowe zastosowania polecenia Grep do wyszukiwania wzorców w plikach tekstowych. Istnieje wiele innych opcji i możliwości, które można dostosować w zależności od konkretnych potrzeb wyszukiwania.
Wyrażenia regularne
Wyrażenia regularne (ang. regular expressions) to sekwencje znaków, które definiują wzorce wyszukiwania w tekście.
Są one szeroko stosowane w różnych językach programowania oraz
w narzędziach takich jak Grep, do przetwarzania i manipulacji tekstowych. Wyrażenia regularne umożliwiają precyzyjne wyszukiwanie, dopasowywanie i manipulację tekstowymi wzorcami.
Podstawowe składniki wyrażeń regularnych to:
Zwykłe znaki
Zwykłe znaki w wyrażeniu regularnym reprezentują same siebie. Na przykład, litera „a” w wyrażeniu regularnym odpowiada dokładnie znakowi „a” w tekście.
Znaki specjalne
Znaki specjalne mają znaczenie specjalne i służą do tworzenia zaawansowanych wzorców. Przykłady znaków specjalnych to:
`.` (kropka) - dopasowuje dowolny pojedynczy znak,
`*` - dopasowuje 0 lub więcej wystąpień poprzedzającego znaku,
`+` - dopasowuje 1 lub więcej wystąpień poprzedzającego znaku,
`?` - dopasowuje 0 lub 1 wystąpienie poprzedzającego znaku,
`|` (kreska pionowa) - oznacza alternatywę,
`()` (nawiasy okrągłe) - grupowanie wyrażenia.Metaznaki
Metaznaki to kombinacje znaków specjalnych, które tworzą bardziej złożone wzorce. Na przykład:
`\d` - dopasowuje cyfry (od 0 do 9),
`\w` - dopasowuje litery, cyfry i znak podkreślenia,
`\s` - dopasowuje białe znaki (spacje, tabulatory itp.),
`\b` - oznacza granicę wyrazu.Klasy znaków
Klasy znaków są używane do dopasowywania konkretnych zestawów znaków. Przykłady klas znaków to:
`[abc]` - dopasowuje jeden znak, który jest literą "a", "b" lub "c",
`[0-9]` - dopasowuje jeden znak, który jest cyfrą od 0 do 9,
`[^0-9]` - dopasowuje jeden znak, który nie jest cyfrą od 0 do 9.W Grep wyrażenia regularne są używane do wyszukiwania wzorców w tekście. Grep analizuje tekst i próbuje dopasować go do określonego wzorca zdefiniowanego jako wyrażenie regularne. Jeśli tekst pasuje do wzorca, Grep wyświetla pasujące linie lub wykonuje inne operacje na dopasowanych fragmentach tekstu.
Załóżmy, że mamy plik tekstowy zawierający listę adresów e-mail a my chcemy wyszukać wszystkie adresy e-mail pasujące do wzorca.
Możemy użyć Grep z wyrażeniem regularnym, np.
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}Grep przeszuka plik tekstowy, dopasuje wszystkie linie zawierające poprawne adresy e-mail i wyświetli je na ekranie.
To tylko podstawowe informacje na temat wyrażeń regularnych. Istnieje wiele innych zaawansowanych funkcji, a także składni dostępnych w wyrażeniach regularnych, które można wykorzystać w Grep i innych narzędziach do przetwarzania tekstu.
Zastosowania Grep i regex
W praktyce Grep i regex znajdują zastosowanie w wielu dziedzinach. Są niezastąpione przy przetwarzaniu logów, gdzie możemy filtrować i analizować zdarzenia systemowe lub aplikacyjne.
Pomagają w analizie plików konfiguracyjnych, gdzie możemy wyszukiwać konkretne ustawienia lub wartości. Dają możliwość filtrowania danych, wyodrębniania informacji i manipulowania tekstem w plikach tekstowych. Są również przydatne podczas analizy kodu źródłowego, gdzie możemy wyszukiwać funkcje, zmienne i inne elementy. Poniżej przedstawiam różne zastosowania narzędzia Grep i wyrażeń regularnych (regex):
1. Przetwarzanie logów:
- Wyszukiwanie konkretnych komunikatów lub błędów w logach systemowych.
- Analiza logów serwera WWW w celu identyfikacji żądań, błędów lub aktywności użytkowników.
- Filtrowanie logów na podstawie określonych kryteriów, takich jak daty, poziomy logowania, identyfikatory itp.
2. Analiza plików konfiguracyjnych:
- Wyszukiwanie określonych ustawień lub wartości w plikach konfiguracyjnych.
- Sprawdzanie poprawności składni plików konfiguracyjnych, takich jak pliki XML, JSON, INI itp.
- Wyodrębnianie danych z plików konfiguracyjnych, takich jak adresy IP, adresy URL, klucze API itp.
3. Filtrowanie danych:
- Wyszukiwanie i wyodrębnianie określonych wzorców danych z dużych plików tekstowych.
- Filtrowanie danych na podstawie określonych kryteriów, takich jak format daty, numeryczne wartości, ciągi znaków itp.
- Usuwanie lub zastępowanie niechcianych fragmentów tekstu, takich jak znaki specjalne, białe znaki, znaczniki HTML itp.
4. Manipulowanie tekstem:
- Zamiana formatu danych, na przykład konwersja daty i czasu do innego formatu.
- Usuwanie duplikatów lub powtórzeń w tekście.
- Formatowanie tekstu, takie jak wyrównywanie, wcięcia, zamiana małych liter na wielkie litery itp.
5. Analiza plików źródłowych:
- Wyszukiwanie funkcji, zmiennych lub innych elementów w kodzie źródłowym programu.
- Wyodrębnianie informacji statystycznych z kodu, takich jak liczba linii, liczba wystąpień określonych wyrażeń itp.
- Automatyzacja procesów refaktoryzacji kodu na podstawie wzorców.
6. Przetwarzanie danych z plików tekstowych:
- Wyodrębnianie danych numerycznych, takich jak liczby, wartości procentowe, wartości walutowe itp.
- Wyszukiwanie lub wyodrębnianie adresów e-mail, numerów telefonów, adresów IP itp.
- Analiza struktury dokumentów, takich jak pliki CSV, pliki dziennika, pliki raportów itp.
Narzędzia Grep i wyrażenia regularne są niezwykle wszechstronne i mogą być wykorzystywane w wielu dziedzinach, gdzie konieczne jest przetwarzanie, analiza i filtrowanie tekstowych danych. Dzięki nim można dokładnie określić wzorce wyszukiwania i manipulować tekstowymi danymi w sposób elastyczny i efektywny.
Podsumowanie i zasoby
W artykule omówiliśmy narzędzia Grep i wyrażenia regularne (regex) oraz ich różnorodne zastosowania w przetwarzaniu, analizie i manipulacji tekstowych danych. Grep pozwala na wyszukiwanie i filtrowanie linii tekstu na podstawie określonych wzorców, podczas gdy wyrażenia regularne umożliwiają precyzyjne definiowanie wzorców tekstowych.
Przykłady zastosowań Grep i regex są liczne. Możemy ich używać do przetwarzania logów, analizy plików konfiguracyjnych, filtrowania danych, manipulowania tekstem oraz analizy kodu źródłowego.
Dzięki nim możemy wyszukiwać wzorce, wykluczać linie, wyszukiwać na początku lub końcu linii, filtrować powtarzające się wzorce i wiele więcej.
Narzędzia Grep i wyrażenia regularne są niezwykle przydatne przy przetwarzaniu i manipulacji tekstowych danych. Zdobycie wiedzy na temat ich składni i możliwości otwiera drzwi do efektywnego przeszukiwania i analizy tekstów. Zdecydowanie polecam eksperymentowanie z różnymi wzorcami aby doskonalić swoje umiejętności w obszarze Grep i wyrażeń regularnych, dzięki temu w jak największym stopniu skorzystamy z dostępnych zasobów a co za tym idzie ułatwimy i przyspieszymy prace w wielu obszarach.

