
W dzisiejszym świecie, dostęp do ogromnej ilości danych dostępnych online jest niezbędny dla wielu zastosowań. Czy to analiza treści witryn internetowych, zbieranie danych do badań naukowych lub po prostu archiwizacja ciekawych artykułów, automatyzacja pobierania i organizacji danych jest kluczowa. W tym artykule przedstawię, jak stworzyć skrypt w Pythonie, który pobiera dane z internetu i organizuje je w przejrzysty sposób na systemie Linux. Naszym celem jest pobieranie treści ze stron internetowych i podstron, tworzenie odpowiednich folderów i umieszczanie zdjęć w odpowiednich miejscach. Dzisiaj zobaczysz jak wygląda automatyzacja Linux za pomocą Python.
Do automatyzacji pobierania danych z internetu będziemy używać dwóch głównych bibliotek Pythona: requests do pobierania treści strony internetowej i BeautifulSoup do analizy struktury HTML.
Jeśli nie masz jeszcze zainstalowanych wymaganych bibliotek, możesz to zrobić za pomocą pip:
pip install requests beautifulsoup4

Sprawdź, czego nauczysz się dzięki kursowi Grafany!
Udostępniamy darmowo ponad godzinny materiał z kursu. Przekonaj się, że jest idealny dla Ciebie!
Chcesz wziąć udział w kursie? Kliknij w link i obejrzyj co Cię czeka: https://asdevops.pl/demo-grafana/
Utworzenie pliku z kodem

Opis działania kodu
- Najpierw definiujemy funkcję pobierz_treść, która używa biblioteki requests, aby pobrać treść strony internetowej na podstawie podanego URL.
- Następnie definiujemy funkcję stwórz_folder, która tworzy folder o podanej nazwie, jeśli jeszcze nie istnieje.
- Funkcja pobierz_i_organizuj to kluczowa część skryptu. Pobiera treść strony internetowej, analizuje ją za pomocą BeautifulSoup, znajduje wszystkie obrazy na stronie i zapisuje je w odpowiednich folderach. Treść strony jest również zapisywana jako plik HTML.
- W głównej funkcji main określamy URL strony internetowej i nazwę folderu głównego, do którego zapisujemy dane.
- Wartości te są przekazywane do funkcji pobierz_i_organizuj, która przetwarza stronę i zapisuje dane.
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
# Funkcja do pobierania treści strony internetowej
def pobierz_treść(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
raise Exception(f'Błąd podczas pobierania treści z {url}')
# Funkcja do tworzenia folderów
def stwórz_folder(nazwa_folderu):
if not os.path.exists(nazwa_folderu):
os.makedirs(nazwa_folderu)
# Funkcja do pobierania i organizowania treści oraz zdjęć
def pobierz_i_organizuj(url, folder_docelowy):
treść = pobierz_treść(url)
soup = BeautifulSoup(treść, 'html.parser')
# Znajdź wszystkie obrazy na stronie
obrazy = soup.find_all('img')
for img in obrazy:
img_url = urljoin(url, img['src'])
img_filename = os.path.basename(urlparse(img_url).path)
img_folder = os.path.join(folder_docelowy, 'zdjęcia')
stwórz_folder(img_folder)
try:
with requests.get(img_url, timeout=10) as response:
if response.status_code == 200:
with open(os.path.join(img_folder, img_filename), 'wb') as img_file:
img_file.write(response.content)
else:
print(f'Błąd podczas pobierania obrazu {img_url}')
except requests.exceptions.RequestException as e:
print(f'Błąd podczas pobierania obrazu {img_url}: {str(e)}')
# Tworzenie folderu dla strony głównej
stwórz_folder(folder_docelowy)
# Zapisz treść strony w pliku txt
with open(os.path.join(folder_docelowy, 'treść.txt'), 'w', encoding='utf-8') as txt_file:
txt_file.write(soup.get_text())
# Znajdź wszystkie linki na stronie
linki = soup.find_all('a', href=True)
for link in linki:
link_url = urljoin(url, link['href'])
link_folder = os.path.join(folder_docelowy, 'podstrony')
stwórz_folder(link_folder)
podstrona_filename = os.path.basename(urlparse(link_url).path)
podstrona_folder = os.path.join(link_folder, podstrona_filename)
stwórz_folder(podstrona_folder)
pobierz_i_organizuj(link_url, podstrona_folder)
# Główna funkcja
def main():
url = input('Podaj adres strony internetowej: ')
folder_główny = 'dane_ze_strony'
pobierz_i_organizuj(url, folder_główny)
if __name__ == '__main__':
main()W powyższym kodzie została dodana również obsługa wyjątków requests.exceptions.RequestException, aby łapać ewentualne błędy związane z pobieraniem obrazów. Jeśli wystąpi błąd, wyświetli się o błędzie a skrypt ma kontynuację. Dzięki temu unikniemy przerwania działania skryptu w przypadku pojedynczych błędów podczas pobierania obrazów.
Uruchomienie kodu
Sprawdzenie środowiska Pythona: Upewnij się, że masz zainstalowanego Pythona na swoim systemie Linux. Wersja Pythona zależy od tego, którą wersję chcesz użyć. Wartość python3 jest zalecana na nowoczesnych systemach Linux.

Przygotowanie bibliotek: Upewnij się, że zainstalowałeś niezbędne biblioteki, takie jak requests, beautifulsoup4 oraz inne, które mogą być potrzebne w zależności od Twoich potrzeb. Możesz to zrobić za pomocą narzędzia pip.
Zapisanie kodu: Zapisz kod do pliku, na przykład jako Pobieranie_danych.py.
Przygotowanie środowiska wirtualnego (opcjonalnie): Jeśli pracujesz w izolowanym środowisku Pythona (co jest zalecane), utwórz i aktywuj środowisko wirtualne za pomocą narzędzia virtualenv. W ten sposób unikniesz konfliktów z innymi pakietami.
sudo apt install python3.11-venv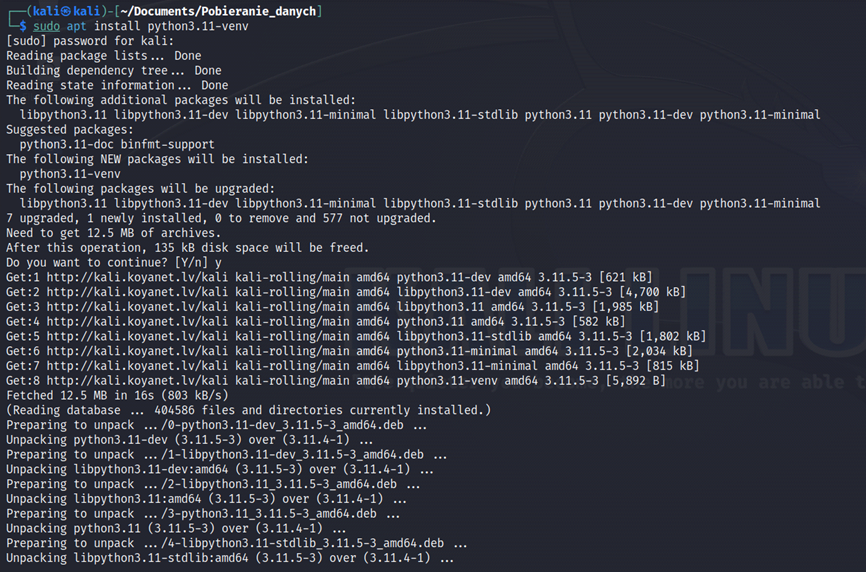
Uruchomienie pliku z kodem

Należy pamiętać, iż strony internetowe mają w sobie zawartych wiele danych i proces pobierania potrwa dosyć długo. Jednak po jakimś czasie można przerwać proces działania skryptu. A to, co do tego momentu zostało zapisane, możemy znaleźć w wskazanym przez nas folderze.
Efekt
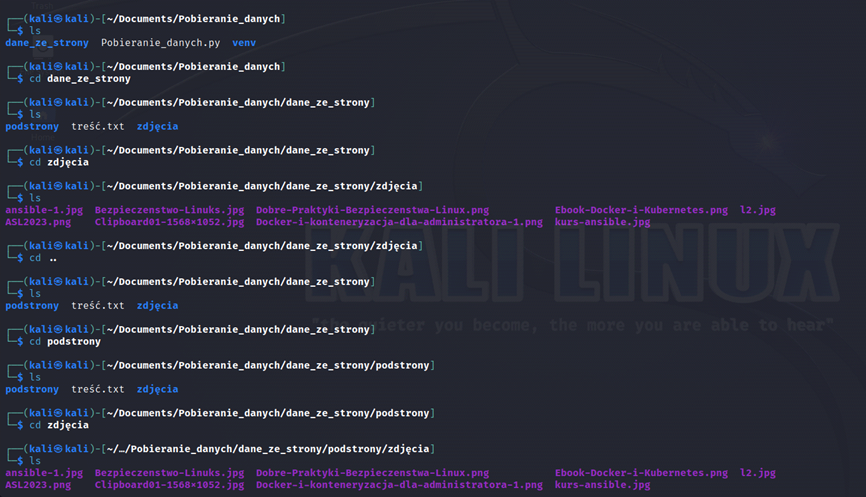
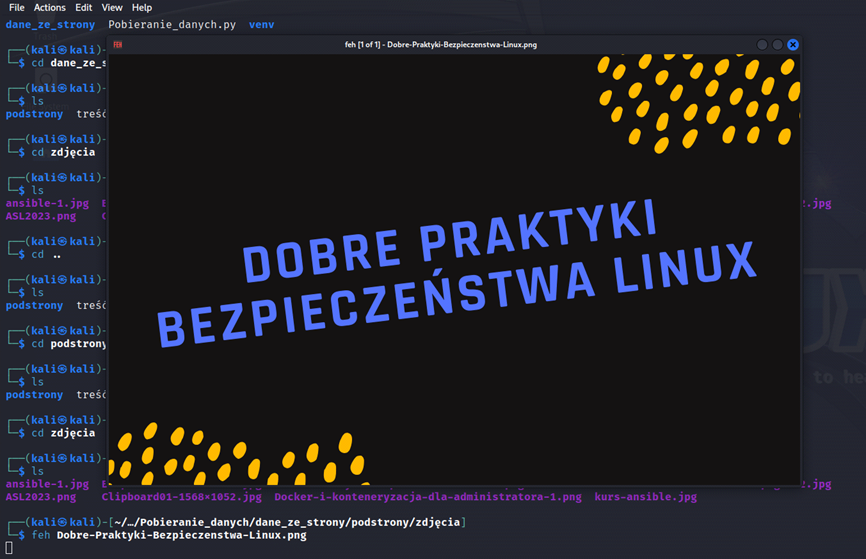
Podsumowanie – Automatyzacja Linux
Powyższy kod umożliwia pobieranie treści i obrazów ze stron internetowych oraz organizowanie ich w odpowiednie struktury folderów. Jest przydatnym narzędziem do automatycznego pobierania treści i obrazów z witryn internetowych oraz ich organizowania w uporządkowany sposób. Dzięki jego funkcjonalności i elastyczności wykorzystuje się go do różnych celów. Takich jak zbieranie danych, monitorowanie stron, analiza zawartości, czy tworzenie archiwum witryn. Jest to narzędzie, które pozwala zaoszczędzić czas i wysiłek podczas pracy z danymi dostępnymi online. Zapewnia także możliwość dostosowania go do konkretnej potrzeby poprzez dodawanie własnych funkcji.
Chcesz wiedzieć więcej na temat administracji? Przeczytaj nasze artykuły, a także weź udział w kursach!

