
Wprowadzenie – Krótka historia i geneza AWK
Krótka historia i geneza AWK sięgają lat 70. XX wieku i związane są z pracą trzech programistów: Alfreda Aho, Petera Weinbergera i Briana Kernaighana. Nazwa „AWK” została utworzona na podstawie pierwszych liter ich imion.
W początkach lat 70. Alfred V. Aho, Peter J. Weinberger i Brian W. Kernighan pracowali w laboratoriach Bell Telephone, które później stały się częścią Bell Labs. W tamtym czasie jednym z popularnych narzędzi do przetwarzania danych była komenda „ed” (edytor). Jednak była ona dość skomplikowana w użyciu i wymagała zaawansowanej wiedzy programistycznej. Z tego powodu programiści z Bell Labs zaczęli szukać bardziej efektywnego rozwiązania do analizy i przetwarzania tekstu.
W 1977 roku Aho, Weinberger i Kernighan stworzyli narzędzie AWK, które było przeznaczone do wygodnej analizy, przetwarzania i manipulacji tekstowymi plikami danych. Głównym celem AWK było umożliwienie programistom przetwarzania dużych zbiorów danych z łatwością i szybkością. Dzięki AWK programiści mogli pisać krótkie skrypty, które wykonywały zaawansowane operacje na tekstach i tabelach danych.
AWK opierał się na kilku ważnych ideach:
- Używanie zwykłego języka, który jest podobny do zwykłych poleceń tekstowych, co znacznie ułatwiało pracę programistom.
- Wyrażenia regularne, które umożliwiały zlokalizowanie i manipulację określonymi wzorcami tekstowymi.
- Domyślne przetwarzanie plików wierszami i kolumnami, które odzwierciedlało strukturę typowych danych tekstowych.
AWK szybko zdobył popularność w środowisku programistycznym ze względu na swoją prostotę, skuteczność i uniwersalność. Dzięki swojej efektywności w przetwarzaniu danych tekstowych, stał się nieodłącznym narzędziem w systemach operacyjnych Unix i stał się dostępny na wielu platformach. AWK jest obszernie wykorzystuje się do analizy logów, generowania raportów, obróbki danych CSV i wielu innych zastosowań. Początkowo AWK był implementowany jako oddzielne polecenie w systemie Unix. Później stał się także częścią języka skryptowego i jest dostępny w większości systemów operacyjnych, w tym Linux, macOS i Windows. Dzisiaj AWK wciąż pozostaje ważnym narzędziem dla programistów i analityków danych, którzy potrzebują efektywnego sposobu analizy i przetwarzania tekstowych danych. Jego prostota, szybkość i wszechstronność sprawiają, że wykorzystuje się go w różnorodnych dziedzinach informatyki i analizy danych.
Mam nadzieję, że ta krótka historia i geneza AWK jest dla Ciebie interesująca.

Sprawdź, czego nauczysz się dzięki kursowi Grafany!
Udostępniamy darmowo ponad godzinny materiał z kursu. Przekonaj się, że jest idealny dla Ciebie!
Chcesz wziąć udział w kursie? Kliknij w link i obejrzyj co Cię czeka: https://asdevops.pl/demo-grafana/
Co to jest AWK i jak działa?
AWK to potężne narzędzie do przetwarzania tekstu i analizy danych, które działa na zasadzie tzw. „języka skryptowego”. Jego głównym celem jest efektywne przetwarzanie i manipulacja strukturą tekstowych plików, zazwyczaj w formie wierszy i kolumn.
Działanie AWK można podzielić na kilka kroków:
- Odczyt plików wejściowych: AWK odczytuje pliki tekstowe lub standardowe wejście (jeśli nie podano plików) wiersz po wierszu. Każdy wiersz traktuje się jako oddzielną jednostkę danych.
- Dzielenie wierszy na pola (kolumny): Domyślnie, AWK dzieli każdy wiersz na pola (kolumny) w oparciu o białe znaki (spacje, tabulacje itp.). Każde pole otrzymuje kolejny numer (pole numer 1, pole numer 2 itd.). Można również użyć niestandardowego separatora, jeśli struktura danych tego wymaga.
- Wykonanie akcji na danych: AWK wykonuje akcje zdefiniowane w skrypcie AWK dla każdego wiersza danych. Skrypt AWK składa się z reguł zdefiniowanych w formacie „warunek {akcja}”. Jeśli warunek jest spełniony dla danego wiersza, zostanie wykonana odpowiadająca mu akcja. Jeśli reguła nie zawiera warunku, akcja będzie dla każdego wiersza.
- Przetwarzanie i manipulacja danych: Podczas wykonywania akcji, AWK może przetwarzać dane, wykonując różne operacje, takie jak: wyświetlanie, modyfikacja, agregacja, obliczenia matematyczne, stosowanie wzorców i wyrażeń regularnych, oraz wiele innych operacji.
- Wyświetlanie wyników: Po zakończeniu przetwarzania danych, AWK wyświetla wyniki na standardowym wyjściu (ekranie). Może je także przekierować do innych plików lub potoków.
Warto zaznaczyć, że AWK jest bardzo elastycznym narzędziem. Pozwala na zaawansowane przetwarzanie i analizę danych, dzięki swojej składni oraz możliwościom wykorzystania wyrażeń regularnych. Jego prosta i zwięzła składnia sprawia, że jest stosunkowo łatwy do nauki i używania. Jest to ważne szczególnie w przypadku prostych zadań przetwarzania tekstów. Jednakże, poznawanie bardziej zaawansowanych technik programowania w AWK może wymagać dodatkowego wysiłku i praktyki.
Właściwości i zalety AWK jako narzędzia programistycznego
AWK posiada wiele właściwości i zalet, które czynią go wyjątkowym narzędziem programistycznym do analizy danych i przetwarzania tekstu. Oto niektóre z najważniejszych cech i korzyści korzystania z AWK:
- Prostota i czytelność składni: Składnia AWK jest dość prosta i czytelna, co ułatwia zrozumienie skryptów AWK nawet dla osób, które nie są doświadczone w programowaniu. Dzięki temu AWK jest świetnym narzędziem dla początkujących i zaawansowanych programistów.
- Wszechstronność: AWK jest wszechstronnym narzędziem, które wykorzystuje się do różnorodnych zadań, takich jak filtrowanie, wycinanie i modyfikowanie danych, przekształcanie formatów, analiza logów, generowanie raportów a także bardziej zaawansowane operacje matematyczne.
- Obsługa plików tekstowych: AWK doskonale radzi sobie z przetwarzaniem danych w formie tekstowej, które często występują w logach, plikach konfiguracyjnych, CSV itp. Pozwala to na wygodne i efektywne operacje na tego typu plikach.
- Wyrażenia regularne: AWK umożliwia wykorzystywanie wyrażeń regularnych do dopasowywania i manipulowania wzorcami tekstowymi, co jest szczególnie użyteczne podczas analizy i przetwarzania danych.
- Potoki (pipelines): AWK łatwo można łączyć z innymi narzędziami za pomocą potoków, co pozwala na efektywne przekierowanie danych z jednego programu do drugiego i łączenie ich funkcjonalności.
- Wbudowana zmienna: AWK posiada wiele wbudowanych zmiennych, takich jak NR (numer bieżącego wiersza), NF (liczba pól w bieżącym wierszu), czy RS (separator rekordów), co ułatwia pracę z danymi i dostęp do różnych informacji o danych.
- Obsługa tablic asocjacyjnych: AWK obsługuje tablice asocjacyjne, co pozwala na skuteczne grupowanie, agregację i analizę danych w bardziej zaawansowany sposób.
- Szybkość przetwarzania: Dzięki swojej zoptymalizowanej implementacji, AWK jest wydajnym narzędziem, które potrafi szybko przetwarzać duże zbiory danych, co jest szczególnie ważne przy analizie logów i innych dużych plików.
- Dostępność na różnych platformach: AWK jest dostępny na wielu platformach w tym na systemach Unix, Linux, macOS oraz Windows. Pozwala to na łatwe wykorzystanie go w różnych środowiskach.
Dzięki powyższym cechom, AWK jest cenionym narzędziem przez programistów, analityków danych i administratorów systemów. Jego prostota, wszechstronność i skuteczność sprawiają, że jest niezastąpiony w wielu scenariuszach, gdzie wymagane jest przetwarzanie i analiza tekstowych danych.
Składnia i struktura polecenia AWK
Składnia polecenia AWK jest dość prosta, ale jednocześnie elastyczna, co pozwala na efektywne przetwarzanie i analizę danych tekstowych. Polecenie AWK ma ogólny format:
awk 'wyrażenie1 { akcja1 } wyrażenie2 { akcja2 } ...' plik1 plik2 ...lub
awk -f skrypt.awk plik1 plik2 ...Gdzie:
- wyrażenie1, wyrażenie2, itd. to warunki, które określają, dla których wierszy zostaną wykonane akcje.
- akcja1, akcja2, itd. to operacje, które mają być wykonane, jeśli warunki wyrażenie1, wyrażenie2, itd. są spełnione.
- plik1, plik2, itd. to pliki tekstowe, na których ma być wykonane polecenie AWK. Opcjonalnie, jeśli nie podamy plików, AWK odczyta dane z wejścia standardowego.
Podstawowa struktura polecenia AWK to zestaw reguł, gdzie każda reguła składa się z wyrażenia warunkowego, a także odpowiadającej mu akcji. Wyrażenie warunkowe może być opcjonalne. Jeśli go nie podamy, akcja wykona się dla każdego wiersza.
Tak wygląda plik z danymi, którego będziemy używać w przykładach.

Przykład prostego polecenia AWK:
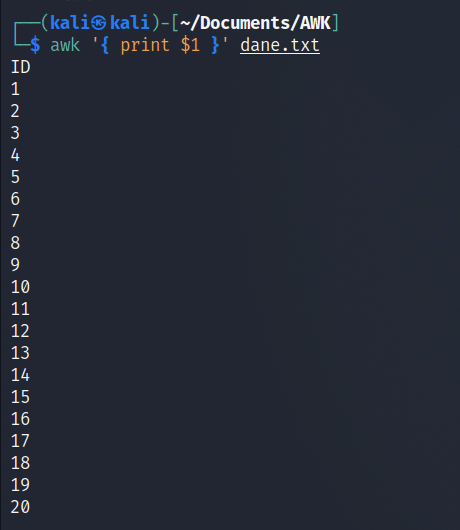
W powyższym przykładzie, wyrażenie warunkowe pominięto. Akcja (w tym przypadku, wyświetlenie pierwszej kolumny) będzie dla każdego wiersza pliku plik.txt.
Przykład polecenia AWK z wyrażeniem warunkowym:
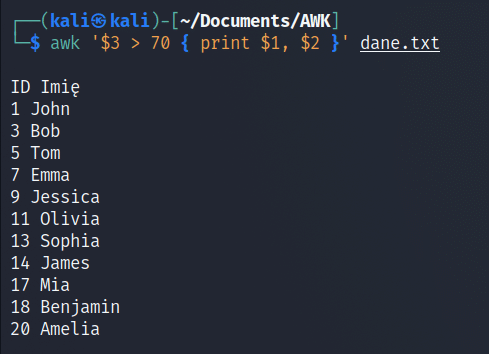
W tym przykładzie, akcja (wyświetlenie pierwszej i drugiej kolumny) będzie tylko dla tych wierszy, dla których trzecia kolumna zawiera liczbę większą niż 70.
Warto zaznaczyć, że polecenie AWK można również umieścić w pliku skryptu, a następnie uruchomić AWK z opcją -f i podać ten plik jako argument. Na przykład, skrypt AWK o nazwie skrypt.awk:
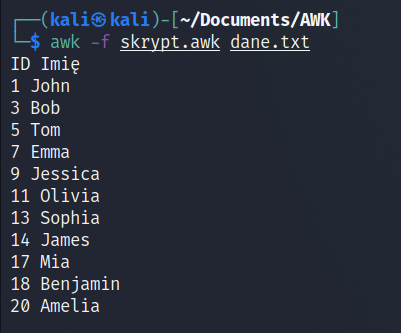
Składnia AWK jest dość elastyczna. Pozwalając na bardziej zaawansowane operacje, takie jak pętle, funkcje i tablice asocjacyjne, co umożliwia bardziej zaawansowane przetwarzanie i analizę danych.
Podsumowanie – Krótka historia i geneza AWK
Artykuł „Krótka historia i geneza AWK” to pierwsza część większego zagadnienia, które będziemy poruszać na blogu. W drugiej części dowiesz się m.in. o zmiennych, a także operatorach w AWK. Przeczytasz także o wyrażeniach warunkowych, a także pętlach. Oprócz tego dowiesz się w jaki sposób wykorzystać AWK do analizy plików tekstowych i nie tylko!
Chcesz wiedzieć więcej na temat bezpieczeństwa? Przeczytaj nasze inne artykuły, a także weź udział w naszych kursach!

